정규화 기법 : 코퍼스 복잡성 감소
표제어 추출(Lemmatization)과 어간 추출(Stemming)은 코퍼스의 복잡성을 감소시키는 기법으로, 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄입니다.
1. 표제어 추출(Lemmatization)
단어의 원형을 찾아서 문서 내에 동일한 원형의 단어가 있는 경우에 하나의 단어로 일반화시키는 방법
표제어 추출은 문서에서 출현한 모든 단어를 그 단어의 표제어로 일반화하여 단어의 수를 줄이는 방법 중 하나입니다.
이를 통해 문서의 복잡성을 낮추고, 효과적인 자연어 처리를 가능하게 합니다.
NLTK - 표제어 추출 도구 : WordNetLemmatizer

표제어 추출은 단어의 형태가 적절히 보존되는 양상을 보이는 특징이 있습니다.
하지만 본래 단어의 품사 정보를 알 수 없는 경우, 의미를 알 수 없는 적절한 단어도 출력한다.
WordNetLemmatizer는 입력으로 단어가 동사 품사라는 사실을 알려준다면 표제어 추출기는 품사의 정보를 보존하면서 정확한 Lemma를 출력하게 됩니다.
표제어 추출은 문맥을 고려하며 수행했을 때의 결과는 해당 단어의 품사 정보를 보존합니다.
하지만 어간 추출을 수행한 결과는 사전에 존재하지 않는 단어일 경우가 많습니다.
2. 어간 추출(Stemming)
어간(Stem)을 추출하는 작업을 어간 추출(stemming)이라고 합니다.
-형태학적 분석을 단순화한 버전
-정해진 규칙만 보고 단어의 어미를 자르는 어림짐작의 작업
어간 추출 후에 나오는 결과 단어는 사전에 존재하지 않는 단어일 수도 있습니다
규칙 기반의 접근을 하고 있으므로 어간 추출 후의 결과에는 사전에 없는 단어들도 포함되어 있습니다.
포터 알고리즘의 어간 추출의 규칙
ALIZE → AL
ANCE → 제거
ICAL → IC
어간 추출 속도는 표제어 추출보다 일반적으로 빠른데, 포터 어간 추출기는 정밀하게 설계되어 정확도가 높습니다.
NLTK에서는 포터 알고리즘 외에도 랭커스터 스태머(Lancaster Stemmer) 알고리즘을 지원합니다.
이번에는 포터 알고리즘과 랭커스터 스태머 알고리즘으로 각각 어간 추출을 진행했을 때, 이 둘의 결과를 비교해보겠습니다.
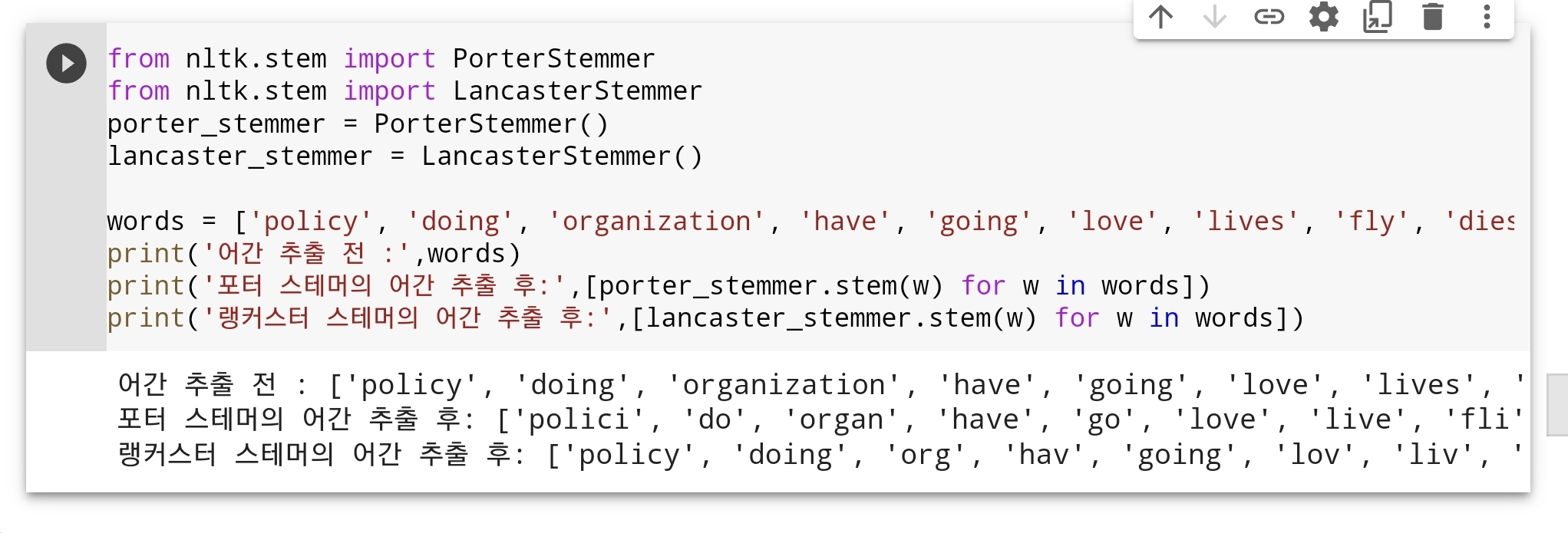
이러한 규칙 기반 알고리즘의 경우 어간 추출을 하고나서 일반화가 지나치게 되거나, 또는 덜 되거나 하는 경우 종종 제대로 된 일반화를 수행하지 못 할 수 있습니다
3. 한국어에서의 어간 추출
한국어는 5언 9품사의 구조
| 체언 | 명사, 대명사, 수사 |
| 수식언 | 관형사, 부사 |
| 관계언 | 조사 |
| 독립언 | 감탄사 |
| 용언 | 동사, 형용사 |
이 중 용언에 해당되는 '동사'와 '형용사'는 어간(stem)과 어미(ending)의 결합으로 구성됩니다.
(1) 활용(conjugation)
활용이란 용언의 어간(stem)이 어미(ending)를 가지는 일을 말합니다.
어간(stem) : 용언(동사, 형용사)을 활용할 때, 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분. 때론 어간의 모양도 바뀔 수 있음(예: 긋다, 긋고, 그어서, 그어라).
어미(ending): 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분이며, 여러 문법적 기능을 수행
활용은 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하는 불규칙 활용으로 나뉩니다.
(2) 규칙 활용
규칙 활용은 어간이 어미를 취할 때, 어간의 모습이 일정합니다.
잡/어간 + 다/어미
규칙 기반으로 어미를 단순히 분리해주면 어간 추출이 됩니다.
(3) 불규칙 활용
불규칙 활용은 어간이 어미를 취할 때 어간의 모습이 바뀌거나 취하는 어미가 특수한 어미일 경우를 말합니다.
어간의 형식이 달라지는 일이 있거나 특수한 어미를 취하는 경우 불규칙활용을 하는 예에 속합니다.
이 경우에는 어간이 어미가 붙는 과정에서 어간의 모습이 바뀌었으므로 단순한 분리만으로 어간 추출이 되지 않고 좀 더 복잡한 규칙을 통해 어간 추출이 가능하다.
'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| 정수 인코딩(Integer Encoding) (0) | 2023.03.13 |
|---|---|
| 정규 표현식(Regular Expression) (0) | 2023.03.13 |
| 불용어(Stopword) (0) | 2023.03.13 |
| 정제(Cleaning) and 정규화(Normalization) (0) | 2023.03.10 |
| 토큰화(Tokenization) (0) | 2023.03.10 |

