1. 코사인 유사도(Cosine Similarity)
코사인 유사도는 두 벡터 간의 방향적 유사성을 측정하는 데 사용됩니다.
코사인 유사도가 1에 가까울수록 두 벡터가 가리키는 방향이 유사하고, 0에 가까울수록 유사하지 않습니다.
음수 값을 가질 경우, 두 벡터가 반대 방향을 가리키고 있다는 것을 의미합니다.
이를 통해 코사인 유사도는 문서 검색, 추천 시스템 등에서 사용되며, 벡터 공간에서의 유사성 측정을 위한 일반적인 방법 중 하나입니다.

similarity=cos(Θ)=A⋅B||A|| ||B||=∑i=1nAi×Bi∑i=1n(Ai)2×∑i=1n(Bi)2
Numpy를 사용해서 코사인 유사도를 계산하는 함수를 구현하고 각 문서 벡터 간의 코사인 유사도를 계산해보겠습니다.
코사인 유사도는 유사도를 구할 때 벡터의 방향(패턴)에 초점을 두므로 코사인 유사도는 문서의 길이가 다른 상황에서 비교적 공정한 비교를 할 수 있도록 도와줍니다.
2. 유사도를 이용한 추천 시스템 구현하기
TF-IDF와 코사인 유사도로 영화의 줄거리에 기반해서 영화를 추천하는 추천 시스템을 만들기
다운로드 링크 : https://www.kaggle.com/rounakbanik/the-movies-dataset
원본 파일은 위 링크에서 movies_metadata.csv 파일을 다운로드 받으면 됩니다.
해당 데이터는 총 24개의 열을 가진 45,466개의 샘플로 구성된 영화 정보 데이터입니다.
pandas 라이브러리는 데이터 분석을 위한 툴로서, 표 형태의 데이터를 다루는 데 특화되어 있습니다.
sklearn 라이브러리는 머신 러닝 알고리즘을 포함한 다양한 머신 러닝 기능들을 제공합니다.
TfidfVectorizer는 문서나 문장들을 벡터화하는 데 사용됩니다.
이를 통해 각 문서 또는 문장을 벡터 형태로 표현하여, 문서 간의 유사도를 계산하거나, 특정 키워드를 추출하는 등의 작업에 활용할 수 있습니다.
cosine_similarity는 두 벡터 간의 코사인 유사도를 계산하는 데 사용됩니다.
이를 통해 벡터 간의 유사도를 측정할 수 있습니다.
예를 들어, 텍스트 분석에서는 문서 간의 유사도를 계산하는 데에 이 함수가 사용됩니다.
[출처 : chatGPT]
다운로드 받은 훈련 데이터에서 상위 2개의 샘플만 출력하여 데이터의 형식을 확인합니다.
...original_titleoverview...titlevideovote_averagevote_count
| 0 | ... | Toy Story | Led by Woody, Andy's toys live happily in his ... 중략 ... | ... | Toy Story | False | 7.7 | 5415.0 |
| 1 | ... | Jumanji | When siblings Judy and Peter discover an encha ... 중략 ... | ... | Jumanji | False | 6.9 | 2413.0 |
코사인 유사도에 사용할 데이터는 영화 제목에 해당하는 title 열과 줄거리에 해당하는 overview 열입니다.
좋아하는 영화를 입력하면, 해당 영화의 줄거리와 유사한 줄거리의 영화를 찾아서 추천하는 시스템을 만들 것입니다.
훈련 데이터의 양을 줄이고 학습을 진행
TF-IDF를 연산할 때 데이터에 Null 값이 들어있으면 에러가 발생합니다.
TF-IDF의 대상이 되는 data의 overview 열에 결측값에 해당하는 Null 값이 있는지 확인합니다.
isnull() 메소드는 데이터프레임에서 null 값인 위치를 True로, 그렇지 않은 값의 위치를 False로 하는 불리언 값을 반환합니다.
결측값을 가진 행을 제거하는 pandas의 dropna()나 결측값이 있던 행에 특정값으로 채워넣는 pandas의 fillna()를 사용
fit_transform() 메소드는 TfidfVectorizer에서 제공하는 메소드로, 텍스트 데이터를 벡터화하는 데에 사용됩니다.
TF-IDF 행렬의 크기는 20,000의 행을 가지고 47,847의 열을 가지는 행렬입니다.
다시 말해 20,000개의 영화를 표현하기 위해서 총 47,487개의 단어가 사용되었음을 의미합니다.
또는 47,847차원의 문서 벡터가 20,000개가 존재한다고도 표현할 수 있을 겁니다.
이제 20,000개의 문서 벡터에 대해서 상호 간의 코사인 유사도를 구합니다.

이제 기존 데이터프레임으로부터 영화의 타이틀을 key, 영화의 인덱스를 value로 하는 딕셔너리 title_to_index를 만들어둡니다.

zip()은 파이썬 내장 함수 중 하나로, 여러 개의 리스트를 받아서, 각 리스트의 같은 위치에 있는 요소들을 튜플로 묶어서 하나의 리스트로 반환합니다. 두 개 이상의 리스트를 인자로 받을 수 있습니다. 리스트의 길이가 서로 다른 경우에는, 가장 짧은 리스트의 길이에 맞추어서 반환됩니다.
선택한 영화의 제목을 입력하면 코사인 유사도를 통해 가장 overview가 유사한 10개의 영화를 찾아내는 함수를 만듭니다.

enumerate() 함수
시퀀스(리스트, 튜플, 문자열 등)를 인자로 받아 각 요소와 그 인덱스를 튜플 형태로 반환하는 iterator를 생성
lambda 인자 : 표현식
"인자"는 입력으로 사용될 변수를 의미하고, "표현식"은 함수의 반환값을 결정하는 식
iloc() 함수
iloc은 DataFrame에서 행(row)과 열(column)을 번호로 선택하기 위한 인덱싱 방법입니다.
iloc을 사용하여 데이터프레임의 행과 열을 정수 인덱스로 참조할 수 있습니다.
영화 다크 나이트 라이즈와 overview가 유사한 영화들을 찾아보겠습니다.
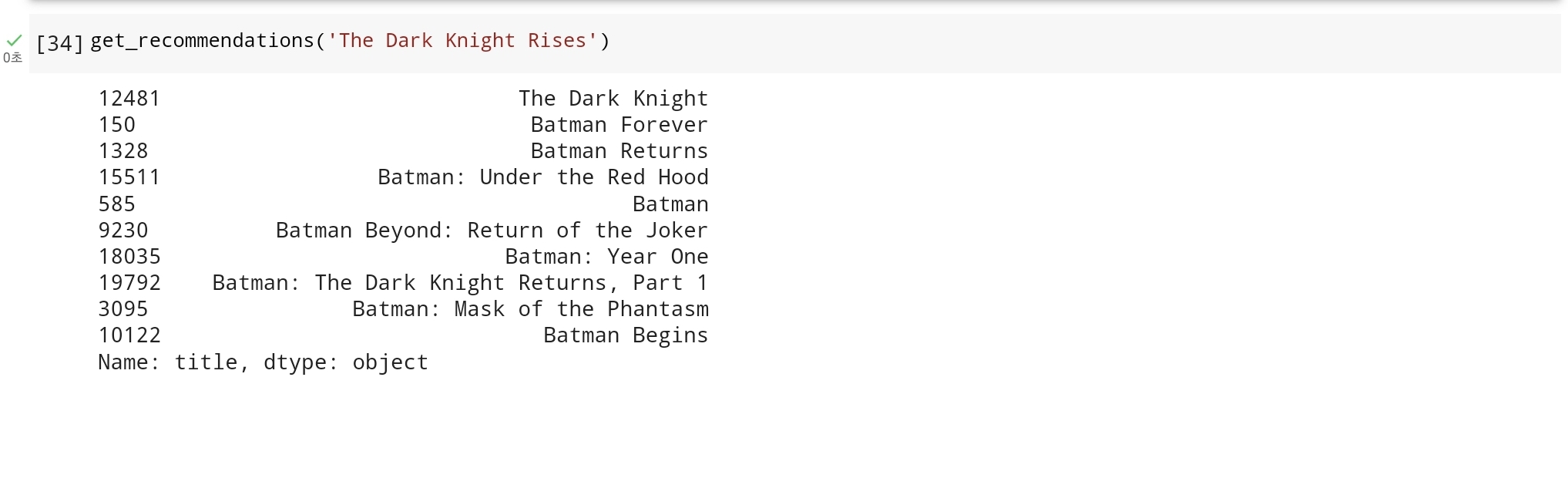
가장 유사한 영화가 출력되는데, 영화 다크 나이트가 첫번째고, 그 외에도 전부 배트맨 영화를 찾아낸 것을 확인할 수 있습니다.
'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| 워드 임베딩(Word Embedding) (0) | 2023.03.15 |
|---|---|
| 여러가지 유사도 기법 (0) | 2023.03.15 |
| TF-IDF(Term Frequency-Inverse Document Frequency) (0) | 2023.03.14 |
| 문서 단어 행렬(Document-Term Matrix, DTM) (0) | 2023.03.14 |
| Bag of Words(BoW) (0) | 2023.03.14 |

