원-핫 벡터 : 단어 벡터 간 유의미한 유사도를 계산할 수 없다
단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화 할 수 있는 방법이 필요합니다.
이를 위해서 사용되는 대표적인 방법이 워드투벡터(Word2Vec)입니다.
원-핫 벡터는 희소 표현 방법이기 때문에 단어 간 유사도를 계산하기 어렵습니다.
이러한 문제를 해결하기 위해 워드투벡터(Word2Vec)와 같은 방법이 개발되었습니다.
워드투벡터는 단어를 고정된 길이의 밀집 벡터로 표현하며, 이를 통해 단어 간 유사도를 계산할 수 있습니다.
워드투벡터는 인공 신경망 모델을 이용하여 학습하는데, 대표적인 모델로는 CBOW(Continuous Bag-of-Words)와 Skip-gram이 있습니다.
위 사이트는 한국어 단어에 대해서 벡터 연산을 해볼 수 있는 사이트입니다.
1. 희소 표현(Sparse Representation)
원-핫 벡터는 표현하고자 하는 단어의 인덱스에 해당하는 원소만 1이고, 나머지 원소는 0으로 표현되는 희소 벡터의 일종입니다.
이러한 표현 방법은 벡터의 차원이 매우 커지게 되면 매우 비효율적일 수 있으며,
각 단어 간 유사성을 표현할 수 없다는 단점이 있습니다.
분산 표현은 단어의 의미를 다차원 공간에 벡터화하는 방법이며, 이를 이용하여 만들어진 벡터를 임베딩 벡터라고 합니다.
이러한 임베딩 벡터를 이용하면 단어 간의 의미적 유사성을 계산하거나 자연어 처리 모델의 입력으로 활용할 수 있습니다.
2. 분산 표현(Distributed Representation)
분산 표현 방법은 분포 가설(distributional hypothesis)이라는 가정에 기반합니다.
이 가정은 '비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다' 라는 것으로, 단어의 의미는 주변 단어와의 상호작용에 의해 형성된다고 가정합니다.
이 가정에 따라, 단어의 의미를 주변 단어들과 함께 고려하여 벡터화하는 것이 분산 표현 방법의 핵심 아이디어입니다.
분산 표현은 분포 가설을 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현합니다.
분산 표현은 일반적으로 고차원의 원-핫 벡터보다 상대적으로 저차원의 벡터로 나타내어지며,
이는 Word2Vec과 같은 방법으로 구현됩니다.
Word2Vec에서는 벡터 차원의 수를 사용자가 설정할 수 있으며, 이 벡터의 각 차원은 실수값을 가집니다.
이러한 방식으로 표현된 임베딩 벡터는 단어 간 유사성을 나타내는 데 효과적이며, 다양한 자연어 처리 작업에 사용될 수 있습니다.
희소 표현이 고차원에 각 차원이 분리된 표현 방법이었다면, 분산 표현은 저차원에 단어의 의미를 여러 차원에다가 분산 하여 표현합니다. 이런 표현 방법을 사용하면 단어 벡터 간 유의미한 유사도를 계산할 수 있습니다. 이를 위한 대표적인 학습 방법이 Word2Vec입니다.
3. CBOW(Continuous Bag of Words)
CBOW는 주변에 있는 단어들의 벡터값을 입력으로 받아 중간에 있는 단어의 벡터값을 예측하는 방법입니다. 즉, 주변 단어들의 벡터값을 평균하여 하나의 입력 벡터를 만들어 예측하는 방법입니다.
데이터 샘플링이 적고 빠르게 학습할 수 있으며, 빈번한 단어에 대한 임베딩이 잘 되는 경향이 있습니다.
반면, Skip-Gram은 중간에 있는 단어의 벡터값을 입력으로 받아 주변에 있는 단어들의 벡터값을 예측하는 방법입니다.
적은 데이터에서도 좋은 성능을 보이며, 드물게 등장하는 단어에 대한 임베딩이 잘 되는 경향이 있습니다.
예측해야 하는 단어를 중심 단어(center word)라고 하고, 예측에 사용되는 단어들을 주변 단어(context word)라고 합니다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도우(window)라고 합니다
윈도우 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는데 이 방법을 슬라이딩 윈도우(sliding window)라고 합니다.
슬라이딩 윈도우를 이용하여 중심 단어와 주변 단어를 선택하고, 이를 이용하여 CBOW나 Skip-Gram 모델을 학습시킵니다. 윈도우의 크기가 작으면 더 적은 단어를 이용하여 학습되므로 일반적으로 윈도우 크기는 5에서 10 정도로 설정됩니다.
CBOW에서 입력층은 윈도우 안에 있는 주변 단어들의 원-핫 벡터를 받아들이고, 출력층에서는 예측하고자 하는 중간 단어의 원-핫 벡터가 레이블로서 필요합니다.
Word2Vec은 은닉층이 1개인 얕은 신경망(shallow neural network)이라는 점입니다.
또한 Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않습니다.
룩업 테이블 연산을 담당하는 층으로 투사층(projection layer)이라고 부르는 것은 Word2Vec의 CBOW 모델에서만 해당됩니다.
Skip-Gram 모델에서는 입력층과 출력층 사이에 하나 이상의 은닉층이 존재합니다.
이 은닉층은 일반적인 신경망과 마찬가지로 활성화 함수를 사용하여 입력값을 변환합니다.
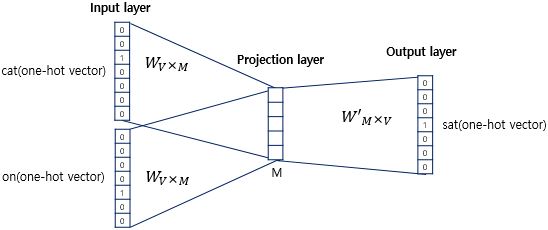
투사층의 크기는 CBOW에서 임베딩 벡터의 차원을 결정합니다.
입력층과 투사층 사이의 가중치 행렬과 투사층과 출력층 사이의 가중치 행렬은 각각 단어 집합의 크기를 V, 투사층의 크기를 M으로 하여 V x M, M x V의 크기를 가집니다.
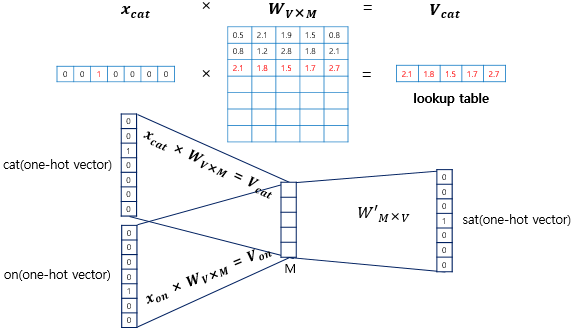
입력 벡터는 원-핫 벡터입니다.
입력 벡터와 가중치 W 행렬의 곱을 통해 룩업 테이블이 이루어집니다.
lookup해온 W의 각 행벡터가 Word2Vec 학습 후에는 각 단어의 M차원의 임베딩 벡터로 간주됩니다.
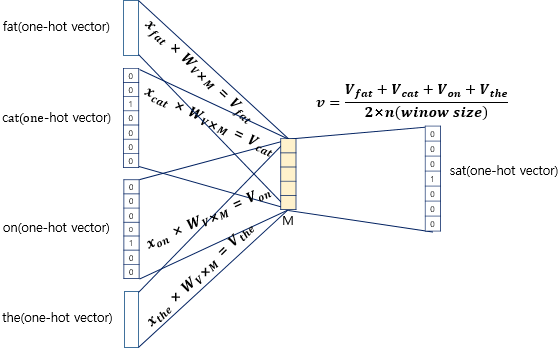
이렇게 주변 단어의 원-핫 벡터에 대해서 가중치 W가 곱해서 생겨진 결과 벡터들은 투사층에서 만나 이 벡터들의 평균인 벡터를 구하게 됩니다.
Skip-Gram은 입력이 중심 단어 하나이기때문에 투사층에서 벡터의 평균을 구하지 않습니다.
skip-Gram 모델은 입력층에서 중심 단어와 가중치 행렬 W를 곱한 결과를 투사층으로 전달합니다.
이 때, 중심 단어 하나에 대해 주변 단어를 예측하는 방식이므로 투사층에서 벡터의 평균을 구하지 않습니다.
대신 투사층에서 얻은 결과 벡터를 출력층과의 손실 함수 계산에 사용합니다.
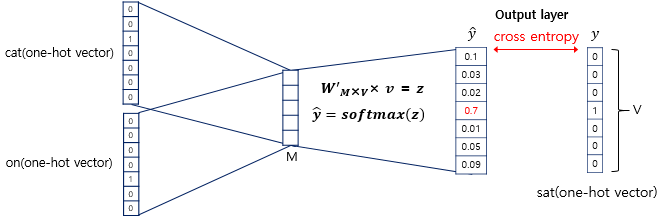
CBOW 모델에서 출력층으로 넘어간 벡터는 소프트맥스 함수를 지나게 되며, 각 원소들의 값은 0과 1 사이의 실수값으로 변환됩니다.이때 각 원소는 해당 단어가 중심 단어일 확률을 나타내며, 모든 원소의 총합은 1이 됩니다
CBOW 모델에서 소프트맥스 함수를 통해 얻어지는 스코어 벡터는 다중 클래스 분류 문제에서 각 클래스에 속할 확률을 나타내는 일종의 예측값입니다.
이 값이 실제 레이블에 가까워지도록 모델의 학습이 이루어져야 합니다.
스코어 벡터의 각 인덱스는 단어 집합에 있는 모든 단어들을 나타내며, 각 단어가 중심 단어일 확률을 나타냅니다.
CBOW 모델에서는 예측값인 스코어 벡터와 실제값인 중심 단어의 원-핫 벡터 간의 오차를 줄이기 위해 크로스 엔트로피 함수를 사용합니다.
크로스 엔트로피 함수는 예측값과 실제값 간의 차이를 계산하는데 사용되며, 손실 함수로 많이 사용됩니다.
크로스 엔트로피 함수에 중심 단어인 원-핫 벡터와 스코어 벡터를 입력값으로 넣고,
cost(𝑦^,y)=−∑j=1Vyj log(𝑦j^)
역전파(Back Propagation)를 수행하면 W와 W'가 학습이 됩니다.
학습된 가중치 행렬 W와 W'의 각 행벡터는 각각의 단어들의 M차원의 임베딩 벡터가 됩니다.
4. Skip-gram
인공 신경망
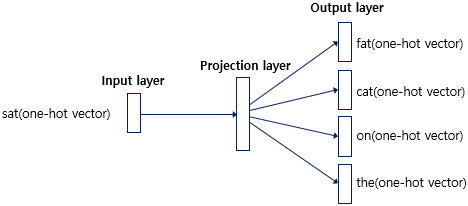
Skip-gram 모델은 중심 단어로부터 주변 단어를 예측하는 방식이기 때문에 투사층에서 벡터들의 평균을 구하지 않습니다.
이러한 특징으로 인해 Skip-gram 모델은 CBOW보다 좀 더 성능이 좋다는 결과가 나온 경우가 많습니다.
5. NNLM Vs. Word2Vec
NNLM은 단어 간 유사도를 구하기 위해 워드 임베딩을 사용했지만 학습 속도와 정확도 면에서 한계가 있었습니다.
이에 Word2Vec은 NNLM의 워드 임베딩 개념을 발전시켜 더욱 빠르고 정확한 워드 임베딩 방법을 제시하였습니다.
NNLM은 다음 단어를 예측하는 언어 모델이 목적이므로 다음 단어를 예측하지만, Word2Vec(CBOW)은 워드 임베딩 자체가 목적이므로 다음 단어가 아닌 중심 단어를 예측하게 하여 학습합니다.
Word2Vec의 CBOW 모델은 중심 단어를 예측하기 위해 주변 단어들을 모두 참고합니다.
따라서 예측 단어의 전, 후 단어들 모두가 모델 학습에 사용됩니다.
이는 NNLM에서 사용된 이전 단어들만을 참고하는 방식과는 차이가 있습니다.
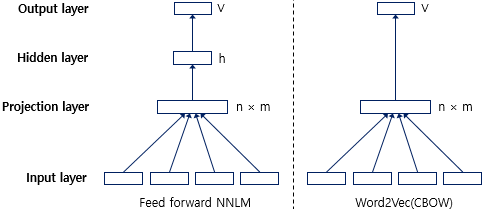
구조도 달라졌습니다. 위의 그림은 n을 학습에 사용하는 단어의 수, m을 임베딩 벡터의 차원, h를 은닉층의 크기, V를 단어 집합의 크기라고 하였을 때 NNLM과 Word2Vec의 차이를 보여줍니다.
Word2Vec의 CBOW 모델에서는 은닉층이 제거되었으나, Skip-gram 모델에서는 여전히 은닉층이 존재합니다.
Skip-gram 모델에서는 중심 단어를 입력으로 받아 투사층에서 벡터 곱을 수행하고, 이어서 은닉층을 거쳐 출력층에 도달합니다.
출력층에서는 softmax 함수를 이용해 다중 클래스 분류 문제를 푸는 방식으로 학습합니다
Word2Vec이 NNLM보다 학습 속도에서 강점을 가지는 이유는 다음과 같은 기법들을 사용하여 모델의 복잡도를 낮추고 계산 속도를 높인 덕분입니다.
- Negative Sampling: 모든 단어에 대해서 Softmax 함수를 사용하면 연산량이 너무 많아집니다. Word2Vec에서는 Negative Sampling이라는 샘플링 기법을 사용하여, 실제 예측값과 다른 무작위 단어들을 샘플링하여 이진 분류 문제로 변환한 후 학습합니다.
- Subsampling: 자주 등장하지 않는 단어는 학습 데이터에서 제외시키는 Subsampling 기법을 사용합니다. 이를 통해 학습 데이터 크기를 줄이고, 빈번하게 등장하는 단어의 정보를 더 잘 반영할 수 있습니다.
- Skip-gram: CBOW 대신 Skip-gram을 사용하면, 예측 단어 주변에 등장하는 단어들을 모두 학습할 수 있으므로 더 많은 정보를 반영할 수 있습니다.
- Hierarchical Softmax: 모든 단어에 대해서 Softmax 함수를 계산하는 대신 이진 트리(binary tree) 형태의 계층적인 구조를 사용하여, 계산 속도를 높이는 Hierarchical Softmax 기법을 사용합니다.
우선 입력층에서 투사층, 투사층에서 은닉층, 은닉층에서 출력층으로 향하며 발생하는 NNLM의 연산량을 보겠습니다.
NNLM에서 입력 단어들의 원-핫 벡터를 투사층에서 곱하면서 워드 임베딩 행렬인 W에 접근하게 됩니다.
이후 투사층의 결과는 은닉층으로 향하여 활성화 함수인 하이퍼볼릭 탄젠트(tanh) 함수를 거치게 됩니다.
그리고 은닉층에서는 각 입력 단어의 임베딩 벡터를 합한 후, 다시 한번 활성화 함수를 거치게 됩니다.
이 활성화 함수 이후 출력층으로 향하는데, 이 출력층에서는 다중 클래스 분류 문제를 위한 소프트맥스 함수를 거치게 됩니다.
따라서 NNLM은 연산량이 매우 많은 모델이므로, 학습 속도가 느린 문제점이 있습니다.
- NNLM : (n×m)+(n×m×h)+(h×V)
여기서 n은 입력 단어의 크기(원-핫 벡터의 크기), m은 임베딩된 단어의 차원수, h는 은닉층의 크기, V는 전체 단어 집합의 크기입니다.
추가적인 기법들까지 사용하였을 때 Word2Vec은 출력층에서의 연산에서 V를 log(V)로 바꿀 수 있는데 이에 따라 Word2Vec의 연산량은 아래와 같으며 이는 NNLM보다 훨씬 빠른 학습 속도를 가집니다.
Word2Vec은 CBOW와 Skip-gram 두 가지 모델이 존재하는데, 각 모델마다 연산량이 다르기 때문에 식도 달라집니다.
CBOW 모델의 경우 입력 단어의 원-핫 벡터를 입력받아 투사층에서 벡터들의 평균을 구한 후 출력층에서 다음 단어의 확률 분포를 구하는 과정을 거치므로,
연산량이 (n×m)+(m×log(V))입니다.
Skip-gram 모델의 경우 중심 단어를 입력받아 출력층에서 주변 단어의 확률 분포를 구하는 과정을 거치므로,
연산량이 (n×m) + (n×m×h) + (log(V)×h)입니다.
'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| 문서 임베딩 : 워드 임베딩의 평균(Average Word Embedding) (0) | 2023.03.16 |
|---|---|
| 임베딩 벡터의 시각화(Embedding Visualization) (0) | 2023.03.15 |
| 워드 임베딩(Word Embedding) (0) | 2023.03.15 |
| 여러가지 유사도 기법 (0) | 2023.03.15 |
| 코사인 유사도(Cosine Similarity) (2) | 2023.03.14 |


