구글은 임베딩 프로젝터(embedding projector)라는 데이터 시각화 도구를 지원합니다. 학습한 임베딩 벡터들을 시각화해봅시다.
임베딩 프로젝터 논문 : https://arxiv.org/pdf/1611.05469v1.pdf
임베딩 프로젝터(Embedding Projector)는 TensorFlow로 구현된 오픈소스 시각화 도구입니다.
임베딩 프로젝터는 워드 임베딩과 같은 다차원 벡터를 시각화하여 고차원 공간에서의 유사도를 직관적으로 이해할 수 있도록 도와줍니다.
이를 통해 임베딩 공간에서 단어들의 관계를 쉽게 파악하고, 데이터의 패턴을 발견하며, 모델의 성능을 개선할 수 있는 힌트를 얻을 수 있습니다.
임베딩 프로젝터는 구글에서 개발한 TensorFlow의 기능 중 하나이며, 웹 브라우저 상에서 사용할 수 있는 인터페이스를 제공합니다.임베딩 프로젝터를 사용하면 워드 임베딩 공간에서의 단어 간 거리, 유사도, 군집화 등을 시각적으로 확인할 수 있습니다.
또한, 임베딩 프로젝터는 다양한 분석 기능을 제공합니다.
예를 들어, t-SNE(t-distributed stochastic neighbor embedding)와 같은 알고리즘을 사용하여 고차원 데이터를 저차원으로 축소하여 시각화할 수 있습니다.
또한, 데이터셋을 여러 그룹으로 나누고 각 그룹의 특징을 비교할 수 있는 클러스터링 기능도 제공합니다.
임베딩 프로젝터는 다양한 분야에서 사용될 수 있으며, 자연어 처리 분야에서는 워드 임베딩의 시각화와 분석에 널리 활용됩니다.
1. 워드 임베딩 모델로부터 2개의 tsv 파일 생성하기
학습한 임베딩 벡터들을 시각화해보겠습니다. 시각화를 위해서는 이미 모델을 학습하고, 파일로 저장되어져 있어야 합니다. 모델이 저장되어져 있다면 아래 커맨드를 통해 시각화에 필요한 파일들을 생성할 수 있습니다.
!python -m gensim.scripts.word2vec2tensor --input 모델이름 --output 모델이름
2. 임베딩 프로젝터를 사용하여 시각화하기
구글의 임베딩 프로젝터를 사용해서 워드 임베딩 모델을 시각화해보겠습니다. 아래의 링크에 접속합니다.
사이트에 접속해서 좌측 상단을 보면 Load라는 버튼이 있습니다.
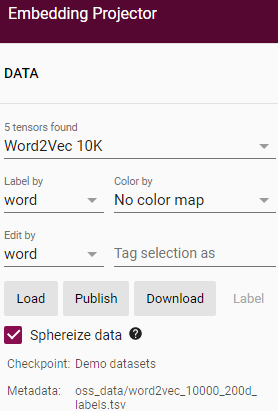
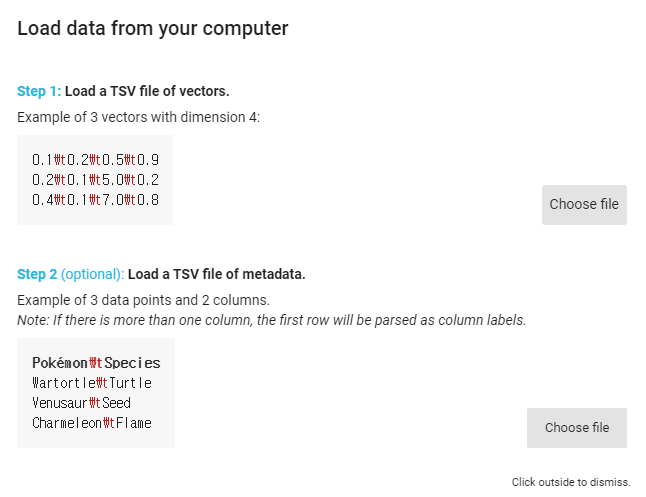
Load라는 버튼을 누르면 아래와 같은 창이 뜨는데 총 두 개의 Choose file 버튼이 있습니다.
파일을 업로드하면 임베딩 프로젝터에 학습했던 워드 임베딩 모델이 시각화됩니다.
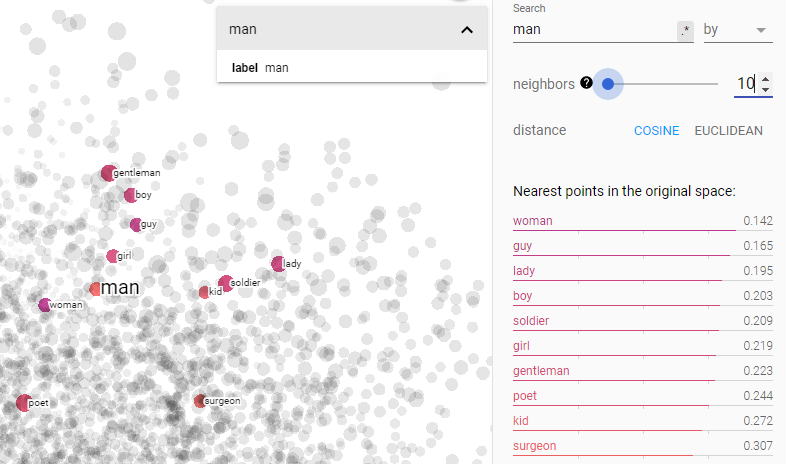
- 프로젝터에 데이터 업로드: 임베딩 프로젝터를 실행하고 시각화하고자 하는 워드 임베딩 데이터 파일을 업로드합니다. 데이터 파일은 텍스트 파일 형식이며, 각 라인에는 단어와 해당 단어의 임베딩 벡터 값이 공백으로 구분되어 있어야 합니다.
- 데이터 설정: 업로드한 데이터 파일에서 시각화할 벡터의 크기와 유사도 측정 방법 등을 설정합니다.
- 시각화: 설정한 데이터를 기반으로 2차원 또는 3차원 공간에 단어 벡터를 시각화합니다. 시각화된 공간에서 단어 간의 유사도와 관계를 살펴볼 수 있습니다.
- 저장 및 공유: 시각화된 결과를 저장하고 다른 사람들과 공유할 수 있습니다. 공유된 시각화 결과는 웹 브라우저를 통해 언제든지 열어볼 수 있습니다.
'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| Doc2Vec으로 공시 사업보고서 유사도 계산하기 (0) | 2023.03.18 |
|---|---|
| 문서 임베딩 : 워드 임베딩의 평균(Average Word Embedding) (0) | 2023.03.16 |
| 워드투벡터(Word2Vec) (0) | 2023.03.15 |
| 워드 임베딩(Word Embedding) (0) | 2023.03.15 |
| 여러가지 유사도 기법 (0) | 2023.03.15 |


