Word2Vec은 단어를 임베딩하는 워드 임베딩 알고리즘이었습니다.
Doc2Vec은 Word2Vec을 변형하여 문서의 임베딩을 얻을 수 있도록 한 알고리즘입니다.
Word2Vec은 단어를 벡터화하는 워드 임베딩 알고리즘이고, Doc2Vec은 문서를 벡터화하는 독립적인 문서 임베딩 알고리즘입니다.
Word2Vec은 단어의 분산 표현(distributed representation)을 학습합니다. 이는 단어를 고정된 차원의 벡터로 표현하면서도 각 단어의 의미와 관계를 보존하는 것을 의미합니다.
Doc2Vec은 문서 전체를 하나의 벡터로 표현합니다. 이를 위해 Doc2Vec은 주어진 문서와 함께 그 문서가 속한 문서 집합(corpus)에 속한 다른 문서들도 함께 학습하는 것이 특징입니다.
Word2Vec과 마찬가지로 파이썬 머신 러닝 패키지인 Gensim을 통해서 쉽게 사용할 수 있습니다.
Gensim은 다양한 텍스트 데이터 전처리 및 분석 기능도 제공하기 때문에 텍스트 데이터를 다루는 데 있어서 유용한 패키지입니다.
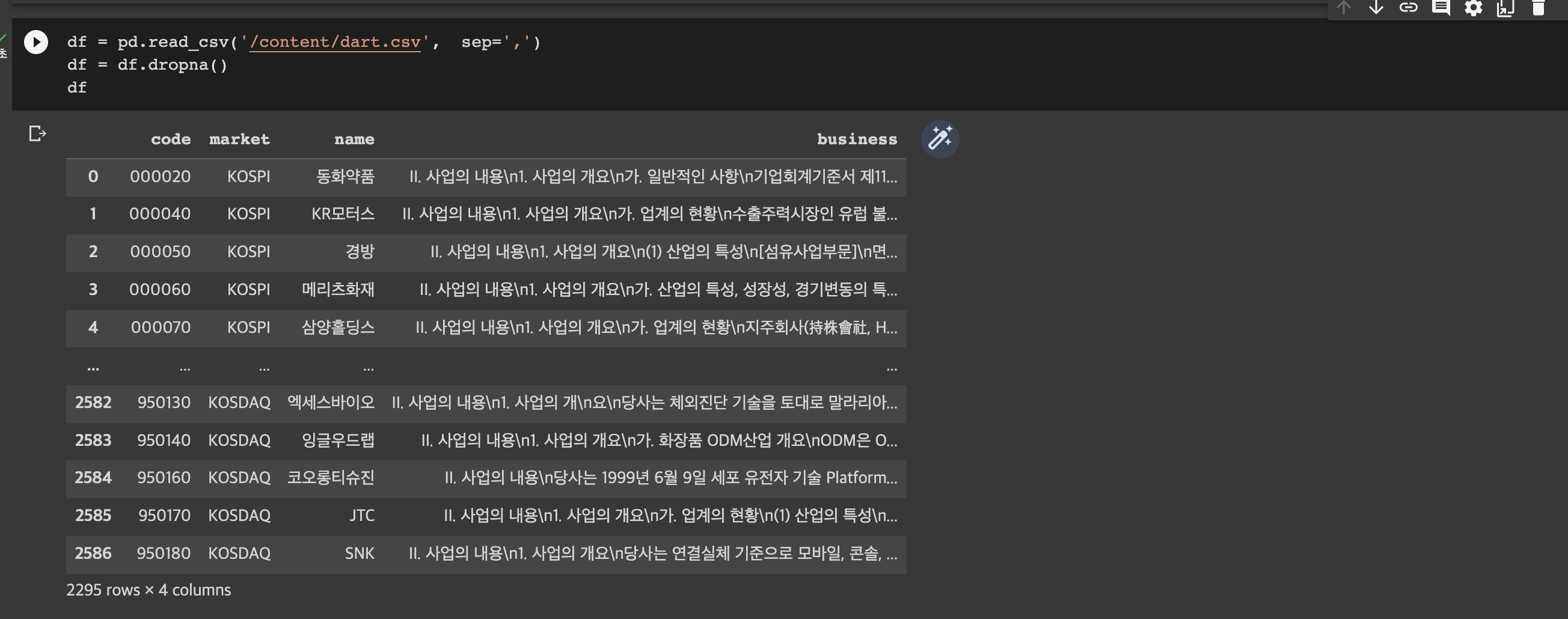
1. 공시 사업 보고서 로드 및 전처리

dart.csv 파일을 데이터프레임으로 로드합니다. 그리고 결측값을 가진 샘플을 제거해줍니다.
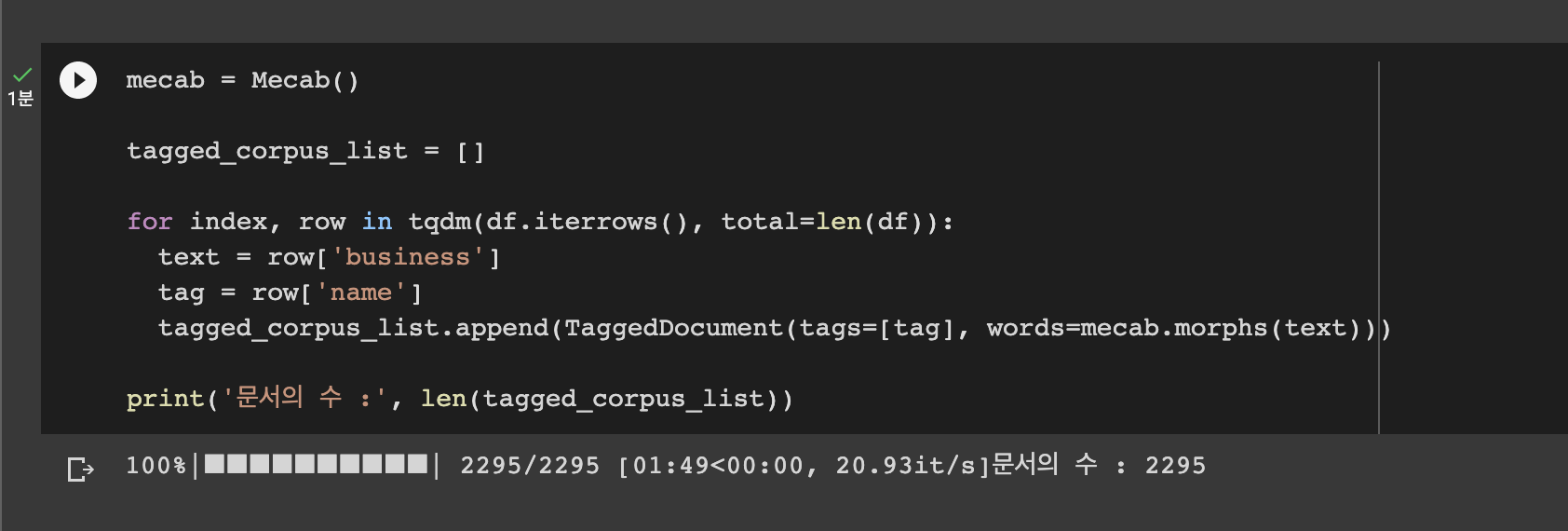
Doc2Vec 학습을 위해서는 해당 문서의 '제목'과 단어 토큰화가 된 상태의 해당 문서의 '본문' 두 가지가 필요합니다.
Doc2Vec의 학습을 위해서는 다음과 같은 것들이 필요합니다.
- 문서 집합: 학습에 사용될 문서들을 모은 집합입니다.
- 각 문서의 제목: 학습에 사용될 각 문서의 고유한 식별자로 사용됩니다.
- 각 문서의 본문: 제목을 제외한 각 문서의 텍스트 내용입니다.
- 단어 토큰화: 문서 내의 단어들을 토큰화하여 학습에 사용될 입력 데이터로 만듭니다.
- 태그: 각 문서의 제목을 토큰화한 것과 같은 형태로 태그를 만들어줍니다. 이 태그는 각 문서의 벡터 표현을 학습하는데 사용됩니다.
이를 통해 각 문서를 벡터화하여 유사도를 계산하고, 새로운 문서가 추가되었을 때 해당 문서의 벡터를 계산하여 이를 다른 문서들과 비교할 수 있습니다.

2. Doc2Vec 학습 및 테스트
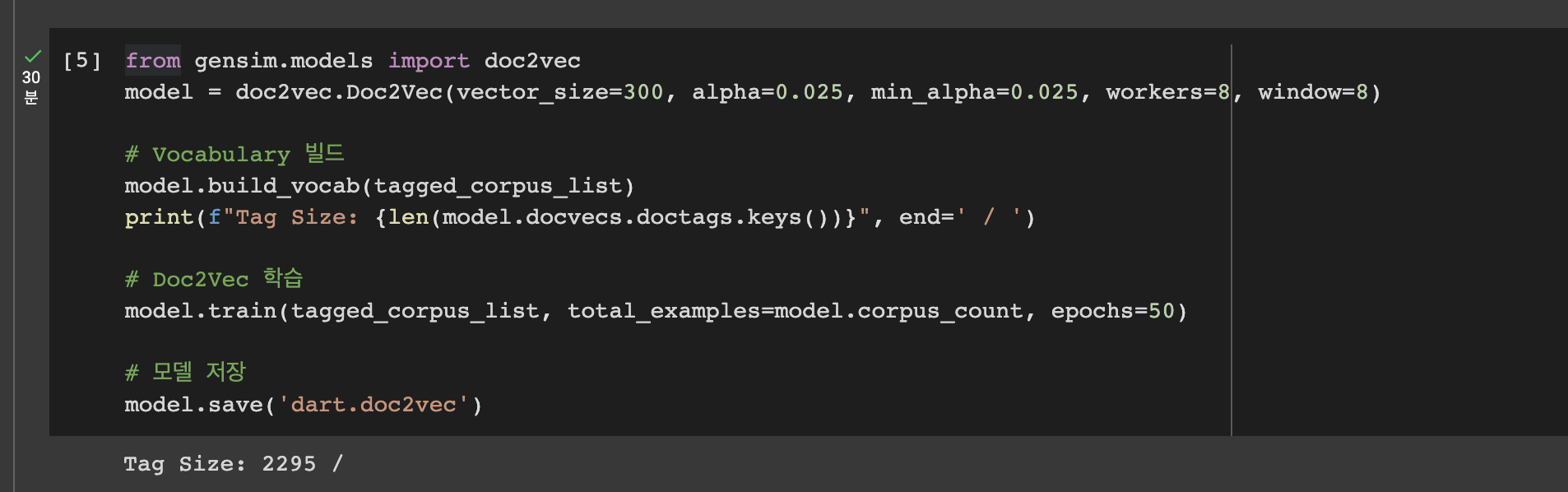
model = doc2vec.Doc2Vec(vector_size=300, alpha=0.025, min_alpha=0.025, workers=8, window = 8)
- vector_size : 각 문서를 벡터로 나타내기 위해 사용되는 차원의 크기. 일반적으로 수백에서 수천의 크기를 갖는다.
- alpha : 학습률. 학습이 얼마나 빨리 진행될지를 제어한다. 보통 0.025에서 0.001 사이의 값을 사용한다.
- min_alpha : 학습률의 최소값. alpha가 이 값보다 작아지면 학습을 멈춘다. 일반적으로 alpha보다 작은 값을 사용한다.
- workers : 학습에 사용할 CPU 코어 수. 일반적으로 시스템의 CPU 코어 수에 따라 조절한다.
- window : 학습 알고리즘이 각 문서에서 앞/뒤로 몇 개의 단어를 보는지를 결정하는 매개변수이다. 일반적으로 5-10 정도의 크기를 사용한다.
model.build_vocab(tagged_corpus_list)
build_vocab() 메소드는 모델의 사전(vocabulary)을 구축합니다.
이 메소드를 호출하기 전에, 모델의 하이퍼파라미터를 먼저 설정해야 합니다.
모델의 사전을 구축하기 위해, 먼저 문서를 태그 형태로 만들고(TaggedDocument), 이를 리스트에 담은 다음 build_vocab() 메소드에 전달합니다.
build_vocab() 메소드를 호출할 때, update 매개변수를 True로 설정하면, 이전에 추가한 문서들의 단어들을 유지한 채, 새로운 문서들의 단어만 추가할 수 있습니다.
model.train(tagged_corpus_list, total_examples=model.corpus_count, epochs=50)
total_examples 인자는 전체 문서 수를 의미하며, epochs 인자는 전체 학습 횟수
코드를 다 수행하고나면 3개의 파일이 생깁니다.
- dart.doc2vec
- dart.doc2vec.trainables.syn1neg.npy
- dart.doc2vec.wv.vectors.npy

'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| 문서 임베딩 : 워드 임베딩의 평균(Average Word Embedding) (0) | 2023.03.16 |
|---|---|
| 임베딩 벡터의 시각화(Embedding Visualization) (0) | 2023.03.15 |
| 워드투벡터(Word2Vec) (0) | 2023.03.15 |
| 워드 임베딩(Word Embedding) (0) | 2023.03.15 |
| 여러가지 유사도 기법 (0) | 2023.03.15 |


