임베딩은 단어나 문장을 벡터 형태로 표현하는 기술입니다.
따라서 특정 문장 내의 단어들의 임베딩 벡터들의 평균값을 구하면 그 문장의 벡터를 얻을 수 있습니다.
이를 활용하여, 문서의 벡터를 구하고 분류 모델의 입력으로 사용하는 방법이 있습니다.
이 경우, 단어의 순서나 문법적인 정보가 반영되지 않아서 성능이 다소 떨어질 수 있지만, 임베딩이 잘 학습되어 있다면 상대적으로 적은 계산 비용으로 효과적인 분류 모델을 구축할 수 있습니다.
1. 데이터 로드와 전처리

from tensorflow keras.datasets import imdb
Keras에서 제공하는 imdb 데이터셋을 로드할 때 imdb.load_data()와 imdb.data_load() 두 가지 방법이 있습니다.
imdb.load_data() 함수는 미리 정의된 훈련 데이터와 테스트 데이터를 불러옵니다.이미 정수로 인코딩된 데이터셋을 반환합니다.
imdb.data_load() 함수는 데이터셋을 다운로드합니다.
이 함수는 데이터를 다운로드하는 동시에 train과 test 데이터를 나누어주며, 인자로서 num_words를 입력할 경우 데이터셋에서 가장 많이 등장한 상위 num_words개의 단어만을 사용합니다.이 함수는 로드된 데이터를 텍스트 형태로 반환합니다.
따라서, imdb.load_data()는 미리 정의된 데이터를 불러오고, 정수 인코딩을 수행하여 바로 사용할 수 있으므로 간단하게 사용할 수 있습니다.
반면 imdb.data_load()는 다운로드한 데이터를 텍스트 형태로 반환하므로, 사용자가 직접 정수 인코딩을 수행해주어야 합니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
pad_sequences
함수는 시퀀스 데이터의 길이를 맞추기 위해 사용됩니다. 이 함수는 시퀀스 데이터의 길이를 최대 길이(maxlen)로 맞추고, 길이가 부족한 부분은 0으로 채워줍니다.
이 데이터는 이미 정수 인코딩까지의 전처리가 진행되어져 있습니다. .
정수 1이 출력되는데 이는 첫번째 리뷰가 긍정 리뷰임을 의미합니다.
각 리뷰의 평균 길이를 계산해봅시다.
map() 함수를 사용하면 리스트 내의 모든 원소에 대해 지정된 함수를 적용할 수 있습니다.
2. 모델 설계하기
from tensorflow.keras.layers import Dense, Embedding, GloabalAveragePooling1D
GlobalAveragePooling1D()은 입력된 3차원 텐서에서 마지막 축(axis) 방향으로 평균을 계산하여 2차원 텐서를 출력합니다.
이 때, 첫 번째 축 방향으로는 입력된 시퀀스 길이를 그대로 유지하고, 두 번째 축 방향으로는 해당 시퀀스의 모든 벡터들의 평균 벡터를 계산합니다.
이렇게 구한 평균 벡터는 해당 문장의 모든 단어 벡터들의 대표값이 되어 텍스트 분류에 사용됩니다.
이후에는 이진 분류 문제이므로, 시그모이드 함수를 활성화 함수로 사용하는 뉴런 1개를 출력층으로 배치하여 모델을 완성합니다.
Fully connected layer(FC layer)
Fully connected layer(FC layer)란, 인공 신경망 모델에서 입력층과 출력층 사이에 존재하는 층으로, 모든 뉴런이 이전 층의 모든 뉴런과 연결된 형태를 가지고 있는 층을 의미합니다.
즉, 각 뉴런이 이전 층의 모든 뉴런의 출력값에 가중치를 곱하여 합한 값을 활성화 함수에 적용하여 출력값을 계산하는 형태입니다.
이러한 구조로 인해, FC layer는 입력 데이터에 대한 복잡한 비선형 함수를 학습할 수 있는 능력을 가지고 있습니다.
FC layer는 보통 분류 문제에서 출력층 이전에 사용되며, 출력층의 뉴런 수와 동일한 수의 뉴런을 가집니다.
이 때, 출력층의 뉴런 수는 문제의 클래스 수와 동일하게 설정하며, FC layer에서 학습된 가중치와 편향을 사용하여 입력 데이터를 출력층의 뉴런 수만큼의 차원으로 매핑하게 됩니다.
FC layer는 기본적으로는 DNN(Deep Neural Network)에서 사용되며, 이미지 분류, 객체 인식, 자연어 처리 등 다양한 분야에서 사용됩니다.
embedding layer
Embedding Layer는 단어를 고정된 길이의 밀집 벡터(dense vector)로 변환하는 역할을 합니다.
이렇게 변환된 벡터는 다음 레이어로 전달되어 모델링이 진행됩니다.
예를 들어, 텍스트 분류 작업을 수행하는 모델에서는 Embedding Layer를 사용하여 입력 텍스트를 밀집 벡터로 변환한 후, 이 벡터를 다음 레이어인 fully connected layer에 입력하여 분류 작업을 수행합니다. Embedding Layer를 사용하면 단어 간 유사도를 반영한 벡터 표현을 얻을 수 있습니다. 이는 전통적인 one-hot encoding 방식과 달리 단어의 의미와 문맥 정보를 보존할 수 있어서, 자연어 처리 분야에서 중요한 역할을 합니다.
global average pooling layer
Global Average Pooling Layer는 Convolutional Neural Network에서 Feature Map으로부터 Global Average Pooling을 통해 고정된 크기의 feature vector를 얻는 기법입니다.
Convolutional Neural Network에서 이를 통해 연산량을 줄이고, overfitting을 방지하고, feature map의 위치 정보를 보존하며, 일반화 성능을 향상시킬 수 있습니다.
Global Average Pooling Layer는 입력된 feature map에서 모든 위치의 값을 더한 후 전체 element의 수로 나누어 평균을 구하며, 이렇게 구한 평균값을 사용하여 고정된 크기의 feature vector를 얻습니다.
이때, Global Average Pooling Layer는 일반적으로 Flatten layer를 대신하여 사용될 수 있습니다.
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
EarlyStopping 콜백은 학습이 더 이상 개선되지 않을 때 자동으로 학습을 멈춥니다. 이를 통해 과적합(overfitting)을 방지할 수 있습니다.
ModelCheckpoint 콜백은 학습 도중 가장 좋은 모델을 저장해주는 역할을 합니다. 즉, 학습 도중에 가장 좋은 성능을 보인 모델의 가중치(weight)를 저장하므로, 학습이 끝난 후에 가장 좋은 모델을 사용할 수 있습니다.
es = EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=4
콜백 함수를 생성할 때 monitor 파라미터에는 모니터링할 지표를 지정하고, mode 파라미터에는 모니터링할 지표의 최소값 또는 최대값을 지정합니다. 예를 들어, monitor='val_loss'와 mode='min'으로 설정하면 검증 손실(validation loss) 지표를 모니터링하고, 검증 손실이 감소하다가 증가하기 시작하면 학습을 종료시킵니다.
verbose 파라미터는 콜백 함수의 로그 출력을 조절합니다. verbose=1로 설정하면 학습 도중에 콜백 함수의 로그가 출력되고, verbose=0으로 설정하면 로그가 출력되지 않습니다.
patience 파라미터는 검증 손실이 개선되지 않은 에포크 횟수를 지정합니다. 예를 들어, patience=4로 설정하면 검증 손실이 4번의 에포크 동안 개선되지 않으면 학습을 종료합니다.
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['acc']
- loss 파라미터는 손실 함수를 설정하는데 사용되며, 여기서는 이진 분류 문제를 다루기 때문에 binary_crossentropy를 사용합니다.
- optimizer 파라미터는 최적화 알고리즘을 설정하는데 사용되며, 여기서는 adam 알고리즘을 사용합니다.
- Adam(Adaptive Moment Estimation)은 모멘텀(momentum)과 AdaGrad 알고리즘을 합친 것으로, 딥 러닝 모델의 최적화에 사용되는 일종의 경사 하강법 알고리즘입니다.
- metrics 파라미터는 평가 메트릭을 설정하는데 사용되며, 여기서는 모델의 정확도를 평가하기 위해 acc를 사용합니다.
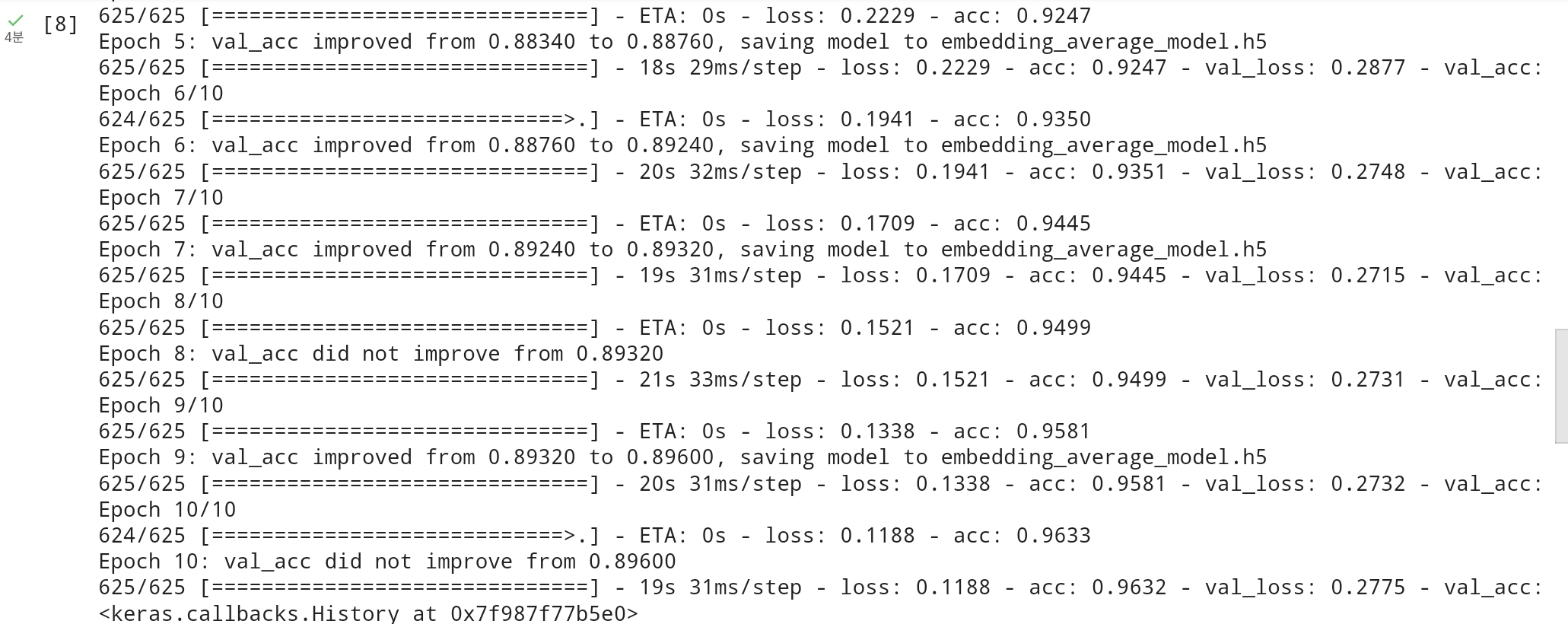
model.fit(X_train,y_train,batch_size=32,epochs=10,callbacks=[es,mc],validation_split=0.2)
- batch_size : 한번에 처리할 데이터 개수
- epochs : 학습 데이터 전체를 몇 번 반복하여 학습할 것인지 결정하는 하이퍼파라미터
- callbacks : 학습 도중에 사용할 콜백 함수들을 리스트로 전달합니다. EarlyStopping과 ModelCheckpoint를 사용합니다.
- validation_split : 학습 데이터 중 일부를 검증 데이터로 사용합니다. 이 비율을 지정합니다.
학습이 끝난 후에 테스트 데이터에 대해서 평가합니다.

'딥러닝 > [딥 러닝을 이용한 자연어 처리 입문]딥러닝' 카테고리의 다른 글
| Doc2Vec으로 공시 사업보고서 유사도 계산하기 (0) | 2023.03.18 |
|---|---|
| 임베딩 벡터의 시각화(Embedding Visualization) (0) | 2023.03.15 |
| 워드투벡터(Word2Vec) (0) | 2023.03.15 |
| 워드 임베딩(Word Embedding) (0) | 2023.03.15 |
| 여러가지 유사도 기법 (0) | 2023.03.15 |


